
OCI 上的Hadoop 工作负载简介
6月 2022
大数据 Hadoop
OCI Ampere A1 实例
Ampere — 赋能未来
Oracle Cloud Infrastructure (OCI)在新的Ampere A1 云原生平台上提供了基于Ampere® Altra®的计算实例。Ampere A1平台可以部署为裸金属服务器或灵活的VM形状,使客户能够完全控制他们的整个云堆栈。Ampere A1 虚拟机形态提供了从1个到80个内核,每核1-64 GB内存的灵活配置,并具多个关键优点,如确定性性能、线性可伸缩性和具有市场上最佳性价比的安全架构。
Apache Hadoop框架是为大型数据集的分布式处理而设计的,这些数据集旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算、存储或两者兼有。在集群中实现时,该软件具有内置的弹性,可以直接处理出错的服务器或服务器中报错的组件。Hadoop由四个主要模块组成,HDFS (Hadoop分布式文件系统),YARN (Yet Another Resource Negotiator), Map Reduce和Hadoop Common。应用程序以各种格式收集数据并将其播种到集群。名称节点是HDFS文件系统的中心部分,它拥有所有数据块的元数据信息,并保存文件系统中所有文件的目录树,并跟踪文件数据在整个集群中的位置。MapR (Map Reduce)作业跨数据节点在HDFS中针对这些数据进处理。
以上所有任务都是计算密集型的,整个集群在高性能组件上能更好地实现。从HDFS提取的数据需要高性能存储,需要在集群中的不同服务器之间进行协调,需要高速网络,必须由数千个任务快速处理,直到最终由reducer聚合以组成最终输出。
在 OCI Ampere A1 虚拟机上评测Hadoop
Oracle云基础设施用于Ampere A1 虚拟机的处理器是业界领先的80核Ampere Altra 处理器。其所有核心都能够持续运行在3.0 GHz的最高频率。利用Ampere 低功耗设计和OCI的高性能基础设施,Ampere A1虚拟机在云中可以提供最佳的性价比。
与x86同类产品相比,OCI的A1虚拟机为大数据应用提供了优越的性价比。对于Hadoop应用程序,由于该架构具有可预测和高度可伸缩的特性,因此使用Ampere 处理器的A1云虚拟机是一个非常值得推荐的选择。
在这个解决方案简介中,我们比较了OCI A1 (Ampere Altra) 虚拟机与OCI S3 Standard (Intel Icelake)、E3 (AMD Rome)和E4 (AMD Milan) flex 虚拟机运行Hadoop TeraSort的性能。
关键收益
一致性和可预测性:Ampere Altra 处理器专为云原生应用而设计,可为 Hadoop 解决方案和激增的工作负载提供一致且可预测的性能。
可扩展性:凭借创新的可横向扩展架构,Ampere Altra 处理器具有更高核心数和极具竞争力的单线程性能。结合所有内核的一致频率特性,OCI Ampere AI 虚拟机的性能优势可达到20%,是大数据工作负载的理想平台。
高能效:行业领先的能效使 Ampere Altra 处理器的性能在达到极具竞争力水平的同时,消耗比竞争对手低得多的电力,即更少的碳足迹。
Ampere Altra
- 80个 64-bit内核,最大主频3.0 GHZ
- 单核 64 KiB i-Cache, 64 KiB d-Cache
- 单核 1MiB L2 Cache
- 32MB SLC (System Level Cache)
- 2x 全宽 (128b) SIMD
- 一致性网格互联架构
内存
- 8x72 bit DDR4-3200 channels
- 支持ECC & RAS
- 最大可配 16x DIMMS (2 DPC) 和 4TB 内存容量
连接
- 128 lanes of PCIe Gen4
- 一致性多路互联
- 4 x16 CCIX lanes
技术特性
- Armv8.2 指令集,SBSA Level 4认证
- 高级电源管理模块
性能
- SPECrate®2017 Integer Estimated: 300
OCI Hadoop 架构
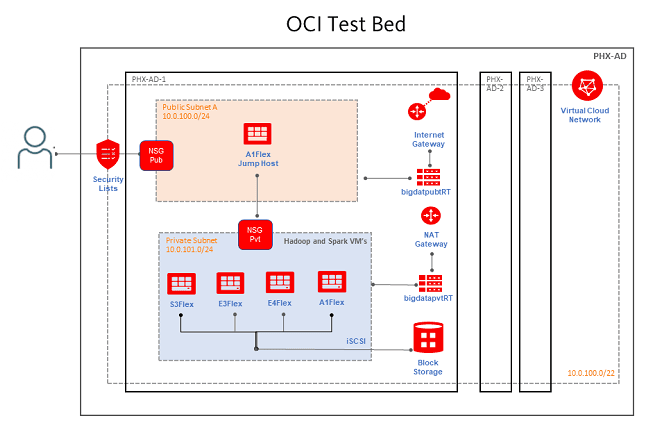
基准测试配置
如上所述,虚拟机是在专用网络空间中提供的。测试平台上安装了Hadoop 3.3.1 (aarch64 binaries)。我们在每个虚拟机上使用Intel HiBench基准测试工具来生成250GB的数据集。在这些虚拟机上运行Hadoop TeraSort基准测试,得到以MB/s为单位的吞吐量。
- 每个架构上都有一个虚拟机,配置如下表所示。
- 所有虚拟机都具有相同的CPU内核/线程、内存和存储配置。
- 所有虚拟机的存储带宽限制为1000 MB/s。8 cpu的x86虚拟机在OCI上的最大带宽为8gb /s。一个具有16个OCPU的A1实例接收的最大带宽为16gb /s。在我们的基准测试中,A1实例被限制为8gb /s,以与x86 VM保持一致。
- 在客户操作系统上做了一些更改,比如禁用透明的大页面和减少VM切换。
- Hadoop中的一些配置参数被调优,以最大限度地利用CPU、内存和存储。
虚拟机和Hadoop的配置信息
| S3Flex | E3Flex | E4Flex | A1Flex | |
|---|---|---|---|---|
| OCPU | 8 | 8 | 8 | 16 |
| Cores/Threads | 8/16 | 8/16 | 8/16 | 16/16 |
| Mem | 96G | 96G | 96G | 96G |
| Arch | x86_64 | x86_64 | x86_64 | aarch64 |
| Kernel | Oracle Linux 8.5 | |||
| Storage | iSCSi 2 x 500G luns, VPU 50, 2 x 480 MBPS | |||
| JDK | JDK11 |
Hadoop 和 Yarn 的配置信息
dfs.block.size - 512M
yarn.scheduler.minimum-allocation-mb - 1024
yarn.scheduler.maximum-allocation-mb - 65536
yarn.scheduler.minimum-allocation-vcores - 1
yarn.scheduler.maximum-allocation-vcores - 15
yarn.nodemanager.resource.cpu-vcores - 16
yarn.nodemanager.resource.memory-mb - 94208
mapreduce.map.memory.mb - 1024
mapreduce.reduce.memory.mb - 3072
mapred.reduce.parallel.copies - 14
mapreduce.reduce.shuffle.parallelcopies - 12
mapreduce.map.java.opts - 2048M
测试基准
Hadoop TeraSort
在每个VM上使用Intel HiBench基准测试工具来生成250GB的数据集。在这些VM上运行Hadoop TeraSort基准测试,获取以MBPS为单位的输出。
测试数据观察
-
CPU利用率徘徊在80%左右,这在高负载条件下是个公平的比较条件。
-
iSCSI lun的磁盘利用率在90%左右,接近容量。 3.A1 虚拟机与传统的x86虚拟机相比表现良好。上面的图表是通过将s3flex作为基线参考点绘制的。
-
经分析,Ampere A1实例的价格性能比英特尔好60%,比AMD形状好10-15%。
注:性价比根据OCI计算价目表计算,适用于16个核心虚拟机(2022年6月)。从16核的价目表中获取每核的价格。所有虚拟机的内存和存储是相同的,因此不考虑。
结论
基于Ampere Altra处理器的Oracle OCI A1实例为Hadoop等大数据解决方案提供了高性能。在为Hadoop工作负载使用OCI Ampere A1虚拟机时,Ampere的性能优势与价格优势相结合,提供了高达60%的性价比优势。
更过信息
脚注
此处包含的所有数据和信息仅供参考,Ampere 保留更改它的权利,恕不另行通知。本文档可能包含技术错误、遗漏和印刷错误,Ampere 没有义务更新或更正此信息。 Ampere 不作任何形式的陈述或保证,包括但不限于对不侵权、适销性或适用于特定目的的明示或暗示保证,并且不承担任何形式的责任。所有信息均“按原样”提供。本文件不是 Ampere 的要约或具有约束力的承诺。使用此处设想的产品需要随后的谈判和最终协议的执行,或者受 Ampere 的商品销售条款和条件的约束。
与 Ampere 测试中使用的不同的系统配置、组件、软件版本和测试环境可能会导致与 Ampere 获得的测量结果不同。
性价比根据OCI计算价目表计算,适用于16个核心虚拟机(2022年6月)。从16核的价目表中获取每核的价格。所有虚拟机的内存和存储是相同的,因此不考虑。
©2022 Ampere Computing 版权所有。Ampere、Ampere Computing、Altra 和“A”标志都是 Ampere Computing 的注册商标或商标。 Arm 是 Arm Limited(或其子公司)的注册商标。本出版物中使用的所有其他产品名称仅用于识别目的,可能是其各自公司的商标。
Ampere Computing® / 4655 Great America Parkway, Suite 601 / Santa Clara, CA 95054 / amperecomputing.com
Ampere Computing
4655 Great America Parkway
Suite 601 Santa Clara, CA 95054

