

Introduction
I saw a blog post about gprofng, a new GNU profiling tool. The example in that blog was a matrix-vector multiplication program written in C. I’m a Java™ programmer, and profiling Java applications is often difficult with tools that are designed for statically-compiled C programs, rather than Java programs that are compiled at runtime. In this blog I show that gprofng is easy to use and useful for digging into the dynamic behavior of a Java application.
The first step was to write a matrix multiplication program. I wrote a full matrix-times-matrix program because it is not more difficult than matrix-times-vector. There are three principal methods: one method to compute the inner-most multiply-add, one method to combine multiply-adds into a single element of the result, and one method to iterate computing each element of the result.
I wrapped the computation in a simple harness to compute the matrix product repeatedly, to make sure the times are repeatable. (See End Note 1.) The program prints out when each matrix multiplication starts (relative to the start of the Java virtual machine), and how long each matrix multiply takes. Here I ran the test to multiply two 8000x8000 matrices. The harness repeats the computation 11 times, and to better highlight the behavior later, sleeps for 920 milliseconds between the repetitions:
$ numactl --cpunodebind=0 --membind=0 -- \
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc -XX:-UsePerfData \
MxV -m 8000 -n 8000 -r 11 -s 920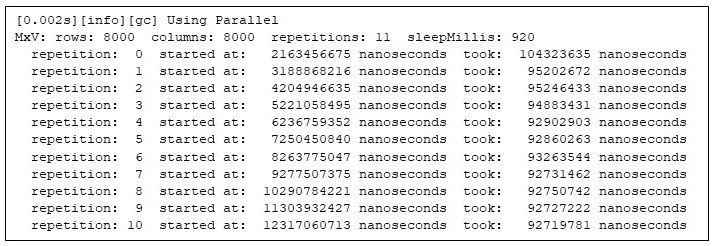 Figure 1: Running the matrix multiply program
Figure 1: Running the matrix multiply program
Note that the second repetition takes 92% of the time of the first repetition, and the last repetition takes only 89% of the first repetition. These variations in the execution times confirm that Java programs need some time to warm up.
The question is: Can I use gprofng to see what is happening between the first repetition and the last repetition that makes the performance improve?
One way to answer that question is to run the program and let gprofng collect information about the run. Fortunately, that is easy: I simply prefix the command line with a gprofng command to collect what gprofng calls an “experiment.”:
$ numactl --cpunodebind=0 --membind=0 -- \
gprofng collect app \
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc --XX:-UsePerfData \
MxV -m 8000 -n 8000 -r 11 -s 920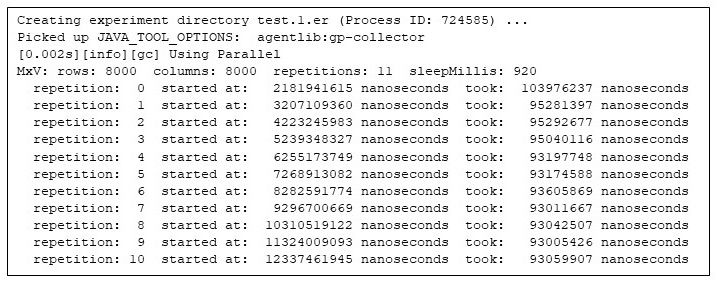 Figure 2: Running the matrix multiply program under gprofng
Figure 2: Running the matrix multiply program under gprofng
The first thing to note, as with any profiling tool, is the overhead that gathering profiling information imposes on the application. Compared to the previous, unprofiled run, gprofng seems to impose no noticeable overhead.
I can then ask gprofng how the time was spent in the entire application. (See End Note 2.) For the whole run, gprofng says the hottest 24 methods are:
$ gprofng display text test.1.er -viewmode expert -limit 24 -functions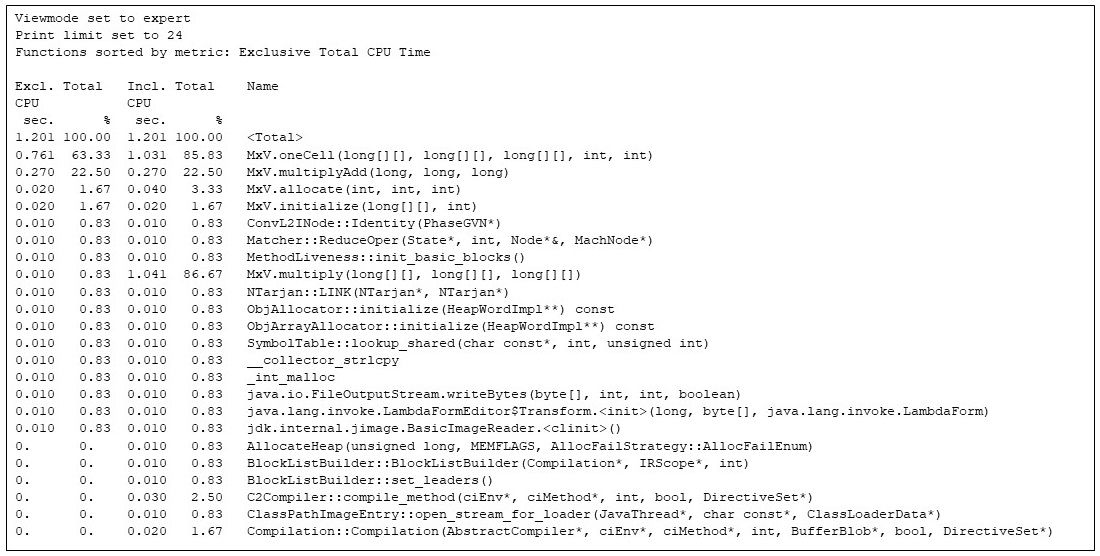
Figure 3: Gprofng display of the hottest 24 methods
The functions view shown above gives the exclusive and inclusive CPU times for each method, both in seconds and as a percentage of the total CPU time. The function named
The methods of the application (the methods from the class MxV) are in there, taking up the vast majority of the CPU time, but there are some other methods in there, including the runtime compiler of the JVM (Compilation::Compilation), and other functions that are not part of the matrix multiplier. This display of the whole program execution captures the allocation (MxV.allocate) and initialization (MxV.initialize) code, which I am less interested in since they are part of the test harness, are only used during start-up, and have little to do with matrix multiplication.
I can use gprofng to focus on the parts of the application that I am interested in. One of the wonderful features of gprofng is that after gathering an experiment, I can apply filters to the gathered data. For example, to look at what was happening during a particular interval of time, or while a particular method is on the call stack. For demonstration purposes and to make the filtering easier, I added strategic calls to Thread.sleep(ms) so that it would be easier to write filters based on program phases separated by one-second intervals. That is why the program output above in Figure 1 has each repetition separated by about one second even though each matrix multiple takes only about 0.1 seconds.
Gprofng is scriptable, so I wrote a script to extract individual seconds from the gprofng experiment. The first second is all about Java virtual machine startup:
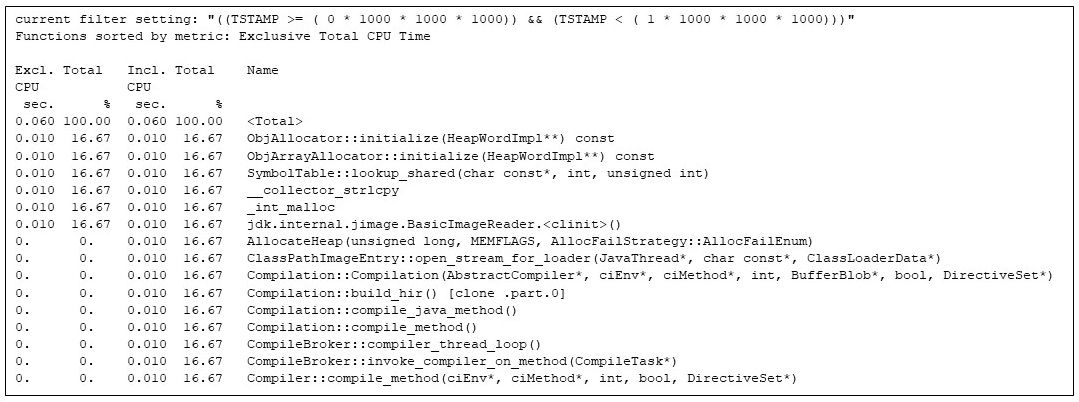
Figure 4: Filtering the hottest methods in the first second. The matrix multiply has been artificially delayed during this second to allow me to show the JVM to start up
I can see that the runtime compiler is kicking in (e.g., Compilation::compile_java_method, taking 16% of the CPU time), even though none of the methods from the application has begun running. (The matrix multiplication calls are delayed by the sleep calls I inserted.)
After the first second is a second during which the allocation and initialization methods run, along with various JVM methods, but none of the matrix multiply code has started yet:
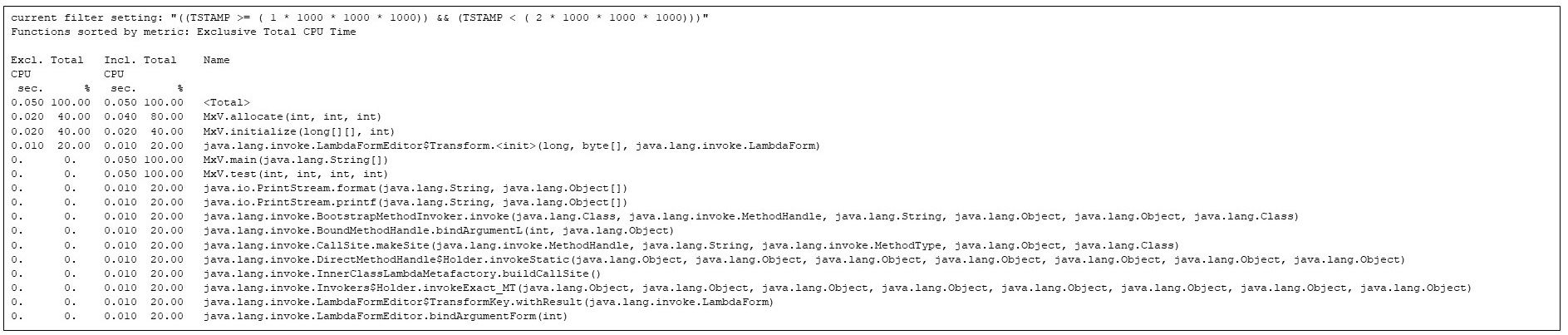
Figure 5: The hottest methods in the second second. The matrix allocation and initialization is competing with JVM startup
Now that JVM startup and the allocation and initialization of the arrays is finished, the third second has the first repetition of the matrix multiply code, shown in Figure 6. But note that the matrix multiply code is competing for machine resources with the Java runtime compiler (e.g., CompileBroker::invoke_compiler_on_method, 8% in Figure 6), which is compiling methods as the matrix multiply code is found to be hot.
Even so, the matrix multiplication code (e.g., the “inclusive” time in the MxV.main method, 91%) is getting the bulk of the CPU time. The inclusive time says that a matrix multiply (e.g., MxV.multiply) is taking 0.100 CPU seconds, which agrees with the wall time reported by the application in Figure 2. (Gathering and reporting the wall time takes some wall time, which is outside the CPU time gprofng accounts to MxV.multiply.)
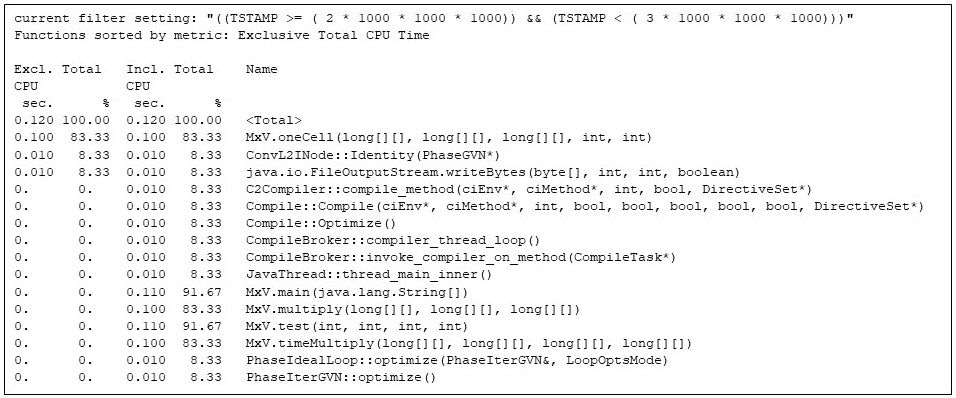
Figure 6: The hottest methods in the third second, showing that the runtime compiler is competing with the matrix multiply methods
In this particular example the matrix multiply is not really competing for CPU time, because the test is running on a multi-processor system with plenty of idle cycles and the runtime compiler runs as separate threads. In a more constrained circumstances, for example on a heavily-loaded shared machine, that 8% of the time spent in the runtime compiler might be an issue. On the other hand, time spent in the runtime compiler produces more efficient implementations of the methods, so if I were computing many matrix multiplies that is an investment I am willing to make.
By the fifth second the matrix multiply code has the Java virtual machine to itself:
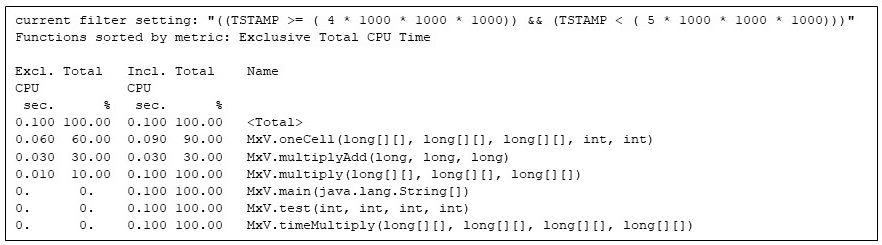
Figure 7: All the running methods during the fifth second, showing that only the matrix multiply methods are active
Note the 60%/30%/10% split in exclusive CPU seconds between MxV.oneCell, MxV.multiplyAdd, and MxV.multiply. The MxV.multiplyAdd method simply computes a multiply and an addition: but it is the innermost method in the matrix multiply. MxV.oneCell has a loop that calls MxV.multiplyAdd. I can see that the loop overhead and the call (evaluating conditionals and transfers of control) are relatively more work than the straight arithmetic in MxV.multiplyAdd. (This difference is reflected in the exclusive time for MxV.oneCell at 0.060 CPU seconds, compared to 0.030 CPU seconds for MxV.multiplyAdd.) The outer loop in MxV.multiply executes infrequently enough that the runtime compiler has not yet compiled it, but that method is using 0.010 CPU seconds.
Matrix multiplies continue until the ninth second, when the JVM runtime compiler kicks in again, having discovered that MxV.multiply has become hot:
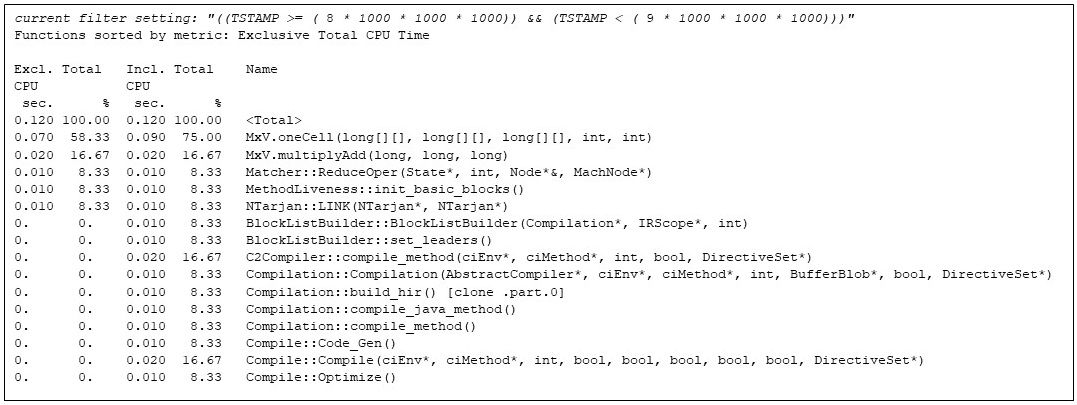
Figure 8: The hottest methods of the ninth second, showing that the runtime compiler has kicked in again
By the final repetition, the matrix multiplication code has full use of the Java virtual machine:
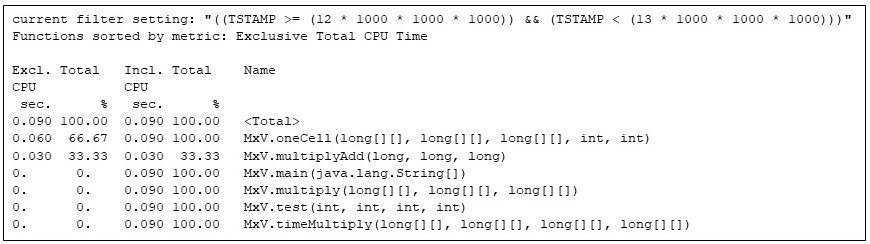
Figure 9: The final repetition of the matrix multiply program, showing the final configuration of the code
Conclusion
I have shown how easy it is to gain insight into the runtime of Java applications by profiling with gprofng. Using the filtering feature of gprofng to examine an experiment by time slices allowed me to examine just the program phases of interest. For example, excluding allocation and initialization phases of the application, and displaying just one repetition of the program while the runtime compiler is working its magic, which allowed me to highlight the improving performance as the hot code was progressively compiled.
Further Reading
For readers who want to learn more about gprofng, there is this blog post with an introductory video on gprofng, including instructions on how to install it on Oracle Linux.
Acknowledgements
Thanks to Ruud van der Pas, Kurt Goebel, and Vladimir Mezentsev for suggestions and technical support, and to Elena Zannoni, David Banman, Craig Hardy, and Dave Neary for encouraging me to write this blog.
End Notes
(1) The motivations for the components of the program command line are:
- numactl --cpunodebind=0 --membind=0 --
- Restrict the memory used by the Java virtual machine to cores and memory of one NUMA node. Restricting the JVM to one node reduces run-to-run variation of the program.
- java
- I am using OpenJDK build of jdk-17.0.4.1 for aarch64.
- -XX:+UseParallelGC
- Enable the parallel garbage collector, because it does the least background work of the available collectors.
- -Xms31g -Xmx31g
- Provide sufficient Java object heap space to never need a garbage collection.
- -Xlog:gc
- Log the GC activity to verify that a collection is indeed not needed. (“Trust but verify.”)
- -XX: -UsePerfData
- Lower the Java virtual machine overhead.
(2) The explanations of the gprofng options are:
- -limit 24
- Show only the top 24 methods (here sorted by exclusive CPU time). I can see that the display of 24 methods gets me well down into the methods that use almost no time. Later I will use limit 16 in places where 16 methods get down to the methods that contribute insignificant amounts of CPU time. In some of the examples, gprofng itself limits the display, because there are not that many methods that accumulate time.
- -viewmode expert
- Show all the methods that accumulate CPU time, not just Java methods, including methods that are native to the JVM itself. Using this flag allows me to see the runtime compiler methods, etc.
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054


